1xBet Korea - 대한민국 최고의 온라인 베팅 플랫폼
온라인 베팅은 현재 매우 인기를 끌고 있으며, 대한민국에서도 그 수요가 증가하고 있습니다. 이러한 인기의 주된 이유 중 하나는 1xBet입니다. 이 플랫폼은 다양한 베팅 옵션과 서비스를 사용자에게 제공하여 다른 플랫폼과 차별화됩니다. 이 글에서는 1xBet과 그 다양한 기능, 특히 1xbet Korea, 1xbet registration, 1xbet download, 1xbet login, 그리고 1xbet app에 대해 자세히 알아보겠습니다.

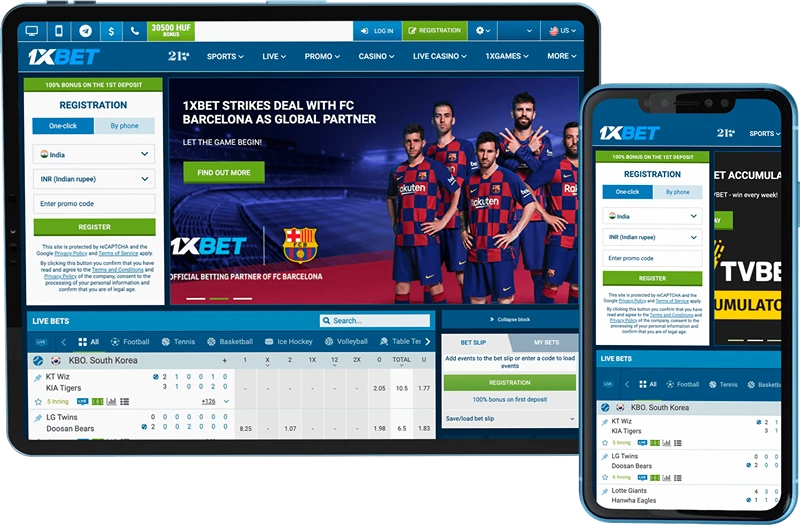
1xBet이란 무엇이며 왜 인기가 있는가?
1xBet은 사용자가 다양한 스포츠와 이벤트에 베팅할 수 있는 온라인 베팅 플랫폼입니다. 이 플랫폼은 전 세계 많은 국가에서 인기를 끌고 있으며, 대한민국에서도 사용자 수가 증가하고 있습니다. 1xbet Korea는 사용자에게 쉽고 안전한 베팅 경험을 제공합니다. 이 플랫폼은 단순한 베팅 웹사이트가 아니라 포괄적인 게임 경험을 제공하여 사용자에게 새로운 즐거움과 흥분을 선사합니다.
1xBet의 인기는 다양한 이유로 설명될 수 있습니다. 첫째, 이 플랫폼은 매우 다양한 스포츠 이벤트와 게임에 베팅할 수 있는 기회를 제공합니다. 사용자는 축구, 농구, 테니스 등 인기 있는 스포츠뿐만 아니라, 보다 특이한 스포츠와 이벤트에도 베팅할 수 있습니다. 둘째, 1xBet은 높은 배당률을 제공하여 사용자에게 더 많은 수익을 기대할 수 있게 합니다. 셋째, 이 플랫폼은 사용이 매우 편리하며, 모바일 앱을 통해 언제 어디서나 쉽게 접근할 수 있습니다.
1xBet의 또 다른 큰 장점은 보안성과 신뢰성입니다. 1xbet registration 과정은 간단하면서도 철저히 보안이 되어 있으며, 사용자의 개인 정보와 금융 거래는 고도로 암호화되어 보호됩니다. 또한, 1xBet은 다양한 결제 옵션을 제공하여 사용자들이 편리하게 입출금을 할 수 있도록 지원합니다. 이러한 모든 요소들이 결합되어 1xBet은 대한민국에서 매우 인기 있는 베팅 플랫폼이 되었습니다.
1xBet Korea: 대한민국에서의 새로운 베팅 차원
1xBet의 대한민국 내 인기는 매일 증가하고 있습니다. 대한민국의 사용자는 이 플랫폼을 통해 다양한 스포츠와 이벤트에 참여할 수 있습니다. 1xbet Korea를 통해 사용자는 국제적인 품질의 베팅 경험을 누릴 수 있으며, 이는 다른 플랫폼에서 쉽게 찾을 수 없습니다. 1xBet은 현지 언어 지원과 다양한 결제 옵션을 제공하여 대한민국 사용자에게 더욱 편리합니다.
1xBet Korea는 특히 대한민국 사용자에게 맞춤형 서비스를 제공하기 위해 현지화된 인터페이스와 고객 지원을 제공합니다. 이는 사용자들이 더 쉽게 접근하고 사용할 수 있도록 돕습니다. 또한, 현지 통화를 지원하여 사용자들이 환전의 번거로움 없이 거래할 수 있습니다. 이러한 현지화 노력은 대한민국 사용자의 만족도를 크게 향상시킵니다.
1xbet Korea는 다양한 스포츠 리그와 이벤트에 대한 폭넓은 베팅 옵션을 제공하며, 이는 한국 사용자들에게 특히 매력적입니다. K리그, 프로야구, 농구 등 국내 스포츠뿐만 아니라 해외 유명 리그와 토너먼트에도 베팅할 수 있습니다. 이러한 폭넓은 선택은 스포츠 팬들에게 더 큰 즐거움을 선사합니다.
또한, 1xbet Korea는 사용자들에게 다양한 프로모션과 보너스를 제공합니다. 신규 사용자들은 1xbet registration을 완료한 후 환영 보너스를 받을 수 있으며, 기존 사용자들도 정기적인 프로모션을 통해 추가 보너스를 받을 수 있습니다. 이러한 혜택은 사용자들이 더 많은 베팅 기회를 가지게 하며, 더 많은 수익을 올릴 수 있도록 돕습니다.

1xbet registration: 등록 방법과 그 혜택
1xBet에 계정을 만드는 것은 매우 쉽습니다. 1xbet registration 과정은 간단하며 몇 단계만 거치면 됩니다. 먼저, 사용자는 1xBet 웹사이트에 접속하여 등록 옵션을 클릭해야 합니다. 그런 다음 필요한 정보를 입력하여 등록 양식을 작성해야 합니다. 등록이 완료되면 사용자는 이메일 또는 전화번호를 통해 계정을 확인할 수 있습니다. 계정을 확인한 후에는 1xbet login 옵션을 통해 계정에 접근할 수 있습니다.
1xbet registration 과정은 사용자의 편의를 위해 매우 간단하게 설계되었습니다. 사용자는 몇 가지 기본 정보만 입력하면 되며, 전체 과정은 몇 분 내에 완료될 수 있습니다. 등록 과정에서 사용자는 사용자 이름, 비밀번호, 이메일 주소 및 전화번호를 입력해야 합니다. 이 정보는 사용자의 계정을 보호하고 안전하게 유지하는 데 필요합니다.
1xbet registration을 완료하면 사용자는 다양한 혜택을 누릴 수 있습니다. 첫째, 신규 사용자는 환영 보너스를 받을 수 있습니다. 이는 첫 입금 시 일정 비율로 추가 금액을 제공하는 형태로, 사용자가 더 많은 베팅을 할 수 있도록 돕습니다. 둘째, 등록된 사용자는 정기적인 프로모션과 이벤트에 참여할 수 있는 자격을 얻게 됩니다. 이러한 프로모션은 사용자가 추가 보너스와 무료 베팅 기회를 얻을 수 있는 좋은 기회입니다.

1xbet registration의 혜택
1xbet registration 과정 중에는 사용자가 제공한 정보가 정확하고 최신 상태인지 확인해야 합니다. 이는 향후 문제를 피하는 데 도움이 됩니다. 또한, 사용자는 강력한 비밀번호를 사용하여 계정의 보안을 유지해야 합니다. 등록 후 사용자는 이메일 또는 전화번호를 즉시 확인하여 계정을 활성화해야 합니다.
1xbet registration의 또 다른 큰 장점은 계정 활성화 후 사용자가 이용할 수 있는 다양한 기능과 서비스입니다. 사용자는 다양한 스포츠 이벤트와 카지노 게임에 베팅할 수 있으며, 높은 배당률과 다양한 베팅 옵션을 즐길 수 있습니다. 또한, 사용자는 1xbet app을 통해 언제 어디서나 베팅을 할 수 있는 편리함을 누릴 수 있습니다.
1xbet registration을 완료한 사용자는 또한 1xBet의 고객 지원 서비스를 이용할 수 있습니다. 고객 지원팀은 사용자가 직면할 수 있는 다양한 문제를 해결하는 데 도움을 줄 수 있으며, 빠르고 효율적인 지원을 제공합니다. 이는 사용자가 항상 안심하고 베팅을 즐길 수 있도록 도와줍니다.
1xbet download: 모바일 앱 다운로드의 이점과 방법
1xBet의 주요 기능 중 하나는 모바일 앱입니다. 사용자는 1xbet app을 다운로드하여 모바일 기기에서 쉽게 베팅할 수 있습니다. 1xbet download 과정은 매우 쉽고 Android 및 iOS 플랫폼 모두에서 사용할 수 있습니다. 사용자는 앱 스토어에서 직접 1xbet app을 다운로드하거나 1xBet 웹사이트에서 다운로드 링크를 받을 수 있습니다.
1xbet download 후 사용자는 앱을 통해 다양한 베팅 옵션을 쉽게 즐길 수 있습니다. 1xbet app을 통해 사용자는 언제 어디서나 좋아하는 스포츠와 이벤트에 베팅할 수 있습니다. 이는 베팅 경험을 더 편리하고 효율적으로 만듭니다. 1xbet app은 사용하기 쉽고 편리한 인터페이스를 제공하여 베팅을 더 빠르고 간편하게 만들어줍니다.
1xbet download 과정은 간단하고 빠르며, 사용자는 몇 분 내에 앱을 설치하고 사용할 수 있습니다. 사용자는 앱을 통해 실시간으로 경기를 확인하고, 다양한 베팅 옵션을 선택하며, 결과를 확인할 수 있습니다. 이는 사용자가 베팅을 더 즐겁고 흥미롭게 만들 수 있도록 돕습니다.
1xbet app 사용의 이점
1xbet download 후 사용자는 앱을 통해 다양한 베팅 옵션을 쉽게 즐길 수 있습니다. 1xbet app을 통해 사용자는 언제 어디서나 좋아하는 스포츠와 이벤트에 베팅할 수 있습니다. 이는 베팅 경험을 더 편리하고 효율적으로 만듭니다. 1xbet app은 사용하기 쉽고 편리한 인터페이스를 제공하여 베팅을 더 빠르고 간편하게 만들어줍니다.
1xbet app의 또 다른 큰 장점은 사용자 친화적인 인터페이스입니다. 앱은 사용자가 쉽게 탐색할 수 있도록 설계되었으며, 필요한 모든 기능을 쉽게 찾을 수 있습니다. 사용자는 앱을 통해 실시간으로 경기를 확인하고, 다양한 베팅 옵션을 선택하며, 결과를 확인할 수 있습니다. 이는 사용자가 베팅을 더 즐겁고 흥미롭게 만들 수 있도록 돕습니다.
1xbet app은 또한 사용자가 최신 이벤트와 프로모션에 대해 신속하게 알림을 받을 수 있도록 도와줍니다. 사용자는 앱을 통해 최신 베팅 기회를 놓치지 않고, 항상 최신 정보를 받아볼 수 있습니다. 이는 사용자가 더 많은 베팅 기회를 가지고, 더 많은 수익을 올릴 수 있도록 돕습니다.
1xbet login: 간편한 로그인 방법과 그 혜택
1xBet에 로그인하는 과정은 매우 쉽습니다. 사용자는 1xbet login 옵션을 클릭하여 사용자 이름과 비밀번호로 로그인할 수 있습니다. 비밀번호를 잊어버린 경우 비밀번호 재설정 옵션을 사용하여 새로운 비밀번호를 설정할 수 있습니다. 로그인 후 사용자는 계정에 접근하여 다양한 베팅 옵션에 참여할 수 있습니다.
1xbet login 과정은 사용자가 빠르고 쉽게 계정에 접근할 수 있도록 설계되었습니다. 로그인 후 사용자는 계정의 모든 기능과 서비스를 완전히 즐길 수 있습니다. 이 로그인 과정은 안전하고 신뢰할 수 있으며, 사용자의 개인 정보와 금융 거래를 보호합니다.
1xbet login 후 사용자는 다양한 베팅 옵션과 기능을 이용할 수 있습니다. 사용자는 스포츠 이벤트, 카지노 게임, 라이브 베팅 등 다양한 옵션에 접근할 수 있습니다. 또한, 사용자는 계정 관리 기능을 통해 입출금, 배당률 확인, 베팅 내역 확인 등을 할 수 있습니다. 이는 사용자가 베팅을 더 효과적으로 관리할 수 있도록 돕습니다.
1xbet login의 혜택
1xbet login 과정은 사용자가 빠르고 쉽게 계정에 접근할 수 있도록 설계되었습니다. 로그인 후 사용자는 계정의 모든 기능과 서비스를 완전히 즐길 수 있습니다. 이 로그인 과정은 안전하고 신뢰할 수 있으며, 사용자의 개인 정보와 금융 거래를 보호합니다.
1xbet login의 또 다른 장점은 사용자가 계정을 쉽게 관리할 수 있다는 점입니다. 사용자는 로그인 후 계정 설정을 변경하고, 입출금 내역을 확인하며, 베팅 내역을 관리할 수 있습니다. 이는 사용자가 베팅을 더 효과적으로 관리할 수 있도록 돕습니다.
또한, 1xbet login을 통해 사용자는 최신 이벤트와 프로모션에 대한 알림을 받을 수 있습니다. 이는 사용자가 새로운 베팅 기회를 놓치지 않도록 도와주며, 항상 최신 정보를 얻을 수 있도록 합니다. 이러한 기능은 사용자가 더 많은 베팅 기회를 가지고, 더 많은 수익을 올릴 수 있도록 돕습니다.
1xBet의 주요 기능: 라이브 베팅, 카지노 게임 등
1xBet은 다른 베팅 플랫폼과 차별화되는 다양한 기능을 제공합니다. 주요 기능 중 일부는 다음과 같습니다.

라이브 베팅
1xBet을 통해 사용자는 라이브 베팅을 할 수 있습니다. 이는 이벤트나 경기가 진행되는 동안 실시간으로 베팅을 할 수 있게 해주는 특별한 기능입니다. 라이브 베팅을 통해 사용자는 경기 상황에 따라 베팅을 조정할 수 있습니다. 라이브 베팅 경험은 1xbet app을 통해 더욱 쉽고 재미있게 즐길 수 있습니다.
라이브 베팅은 사용자가 경기를 실시간으로 관찰하며 베팅을 조정할 수 있게 해줍니다. 이는 사용자가 더 나은 결정을 내리고, 더 많은 수익을 올릴 수 있도록 돕습니다. 예를 들어, 축구 경기를 실시간으로 관찰하며 팀의 경기력을 평가하고, 이에 따라 베팅 금액을 조정할 수 있습니다. 이러한 실시간 조정 기능은 사용자에게 큰 장점을 제공합니다.
또한, 1xbet app을 통해 사용자는 언제 어디서나 라이브 베팅을 즐길 수 있습니다. 이는 사용자가 이동 중에도 베팅을 할 수 있게 해주며, 더 많은 베팅 기회를 제공합니다. 이러한 편리함은 사용자에게 큰 매력으로 다가옵니다.
카지노 게임
1xBet의 카지노 섹션에는 다양한 게임이 포함되어 있습니다. 사용자는 룰렛, 블랙잭, 포커 등 다양한 카지노 게임을 즐길 수 있습니다. 1xbet app을 통해 카지노 게임을 하는 것도 매우 간편합니다. 1xbet Korea 사용자들은 국제적인 수준의 카지노 게임 경험을 즐길 수 있습니다.
카지노 게임은 사용자가 전통적인 베팅 외에도 다양한 게임을 즐길 수 있는 기회를 제공합니다. 이는 사용자가 다양한 베팅 옵션을 가지고, 더 많은 재미를 느낄 수 있도록 돕습니다. 1xBet의 카지노 섹션은 고품질의 그래픽과 사용자 친화적인 인터페이스를 제공하여 게임 경험을 더욱 향상시킵니다.
또한, 1xBet은 라이브 카지노 기능을 제공하여 사용자가 실제 딜러와 실시간으로 게임을 즐길 수 있게 합니다. 이는 사용자가 실제 카지노에 있는 것처럼 느낄 수 있도록 도와주며, 더 현실감 있는 게임 경험을 제공합니다. 이러한 기능은 사용자에게 큰 인기를 끌고 있습니다.
스포츠 베팅
1xBet은 스포츠 베팅에 최적화된 플랫폼입니다. 여기서 사용자는 축구, 크리켓, 농구 등 다양한 스포츠와 이벤트에 베팅할 수 있습니다. 1xbet Korea 플랫폼은 다양한 국가의 경기에 베팅할 기회를 제공합니다. 스포츠 베팅 분야에서 1xbet registration은 베팅과 상금을 안전하고 편리하게 관리할 수 있게 해줍니다.
스포츠 베팅은 많은 사람들에게 매우 인기 있는 활동입니다. 1xBet은 다양한 스포츠 이벤트에 대한 폭넓은 베팅 옵션을 제공하여 사용자에게 더 많은 선택권을 줍니다. 사용자는 자신이 좋아하는 팀이나 선수에게 베팅할 수 있으며, 이는 경기 관람의 재미를 더해줍니다.
또한, 1xBet은 높은 배당률을 제공하여 사용자가 더 많은 수익을 올릴 수 있도록 돕습니다. 이는 사용자가 베팅에 대한 기대감을 높이고, 더 많은 흥미를 느끼게 합니다. 1xBet은 다양한 분석 도구와 통계를 제공하여 사용자가 더 나은 결정을 내릴 수 있도록 도와줍니다.
1xBet의 보너스와 프로모션
1xBet은 신규 사용자와 기존 사용자 모두를 위한 다양한 보너스와 프로모션을 제공합니다. 신규 사용자는 1xbet registration을 완료한 후 환영 보너스를 받을 수 있습니다. 또한, 기존 사용자도 다양한 프로모션을 즐길 수 있습니다. 이러한 보너스와 프로모션은 베팅 경험을 더욱 흥미롭고 유익하게 만듭니다.
1xBet의 보너스와 프로모션은 사용자가 더 많은 베팅 기회를 가지고, 더 많은 수익을 올릴 수 있도록 돕습니다. 예를 들어, 첫 입금 보너스는 사용자가 처음 입금할 때 추가 금액을 제공하여 더 많은 베팅을 할 수 있게 합니다. 또한, 정기적인 프로모션은 사용자에게 추가 보너스와 무료 베팅 기회를 제공합니다.
1xBet은 또한 다양한 이벤트와 토너먼트를 통해 사용자에게 추가 보너스를 제공합니다. 이러한 이벤트는 사용자가 다른 사용자와 경쟁하며, 더 많은 상금을 받을 수 있는 기회를 제공합니다. 이는 베팅의 재미를 더해주며, 사용자가 더 많은 흥미를 느끼게 합니다.
1xbet app: 모바일 기기에서의 편리함과 사용성
1xbet app을 사용하면 사용자가 모바일 기기에서 쉽게 베팅할 수 있습니다. 이 앱은 사용자에게 다양한 이점을 제공합니다.
사용자 친화적인 인터페이스
1xbet app의 인터페이스는 매우 사용자 친화적이며, 사용자가 쉽게 탐색할 수 있습니다. 여기서 사용자는 다양한 베팅 옵션을 쉽게 찾고 즉시 베팅할 수 있습니다. 1xbet download 후 사용자는 앱의 기능을 빠르게 이해하고 쉽게 베팅을 시작할 수 있습니다.
1xbet app은 직관적인 디자인과 간편한 내비게이션을 제공하여 사용자가 베팅을 더 쉽게 할 수 있도록 돕습니다. 이는 사용자가 앱을 처음 사용하는 경우에도 빠르게 적응하고, 다양한 기능을 활용할 수 있게 합니다. 또한, 앱은 빠른 로딩 시간과 안정적인 성능을 제공하여 사용자 경험을 향상시킵니다.
알림과 업데이트
1xbet app은 사용자에게 이벤트와 새로운 프로모션에 대한 알림과 업데이트를 제공합니다. 1xbet login 후 사용자는 이러한 알림을 받을 수 있어 베팅 경험이 더욱 향상됩니다. 이러한 알림과 업데이트는 사용자가 중요한 소식과 베팅 기회를 놓치지 않도록 도와줍니다.
1xbet app을 통해 사용자는 최신 베팅 기회와 프로모션에 대한 실시간 알림을 받을 수 있습니다. 이는 사용자가 항상 최신 정보를 얻을 수 있도록 도와주며, 더 많은 베팅 기회를 제공합니다. 이러한 알림 기능은 사용자가 새로운 이벤트와 프로모션을 빠르게 인지하고, 더 많은 수익을 올릴 수 있도록 돕습니다.
안전성과 신뢰성
1xbet app은 사용자에게 완전히 안전하고 신뢰할 수 있는 베팅 환경을 제공합니다. 여기서 사용자의 개인 정보는 안전하게 보호되며 금융 거래는 철저히 보안됩니다. 1xbet registration과 1xbet login을 통해 사용자는 계정을 완전히 보호할 수 있습니다.
1xbet app은 고도로 암호화된 보안 시스템을 사용하여 사용자의 개인 정보와 금융 거래를 보호합니다. 이는 사용자가 안심하고 베팅을 즐길 수 있도록 도와줍니다. 또한, 1xBet은 정기적인 보안 업데이트를 통해 시스템을 최신 상태로 유지하며, 사용자의 안전을 보장합니다.

1xbet app 사용의 추가 혜택
1xbet app을 사용하면 사용자가 언제 어디서나 베팅할 수 있습니다. 이 앱은 사용자에게 편리하고 안전한 베팅 경험을 제공합니다. 사용자 친화적인 인터페이스와 빠른 성능 덕분에 앱 사용 경험이 원활하고 즐거워집니다. 또한 1xbet app을 통해 사용자들은 고객 지원 서비스와 효과적인 지원을 받을 수 있습니다. 문제가 있을 때 언제든지 고객 지원팀에 연락할 수 있어 신속하고 효과적인 해결책을 받을 수 있습니다.
1xbet app은 또한 다양한 결제 옵션을 제공하여 사용자가 쉽게 입출금을 할 수 있도록 돕습니다. 이는 사용자가 베팅에 집중할 수 있도록 하며, 금융 거래에 대한 걱정을 덜어줍니다. 1xbet app을 통해 사용자는 다양한 결제 방법을 선택하고, 빠르고 안전하게 거래를 완료할 수 있습니다.
1xBet의 결제 옵션: 간편하고 안전한 거래
1xBet은 사용자가 쉽게 결제할 수 있도록 다양한 결제 옵션을 제공합니다. 사용자는 원하는 결제 방법을 통해 간편하게 입출금을 할 수 있습니다. 1xbet South Korea 사용자를 위해 현지 결제 옵션도 제공되어 더욱 편리합니다. 결제 옵션에는 은행 송금, 신용카드 및 직불카드, 다양한 전자 지갑 서비스가 포함됩니다.
1xBet의 결제 과정은 간편하고 신속하게 설계되어 있어 사용자가 편리하고 안전하게 거래할 수 있습니다. 사용자는 편리한 결제 방법을 선택할 수 있으며, 개인 정보가 철저히 보호된다는 점에서 안심할 수 있습니다. 1xBet은 또한 다양한 통화를 지원하여 사용자가 원하는 통화로 거래할 수 있도록 도와줍니다.
결제 과정은 매우 직관적이며, 사용자는 몇 번의 클릭만으로 쉽게 입출금을 완료할 수 있습니다. 이는 사용자가 베팅에 집중할 수 있도록 하며, 금융 거래에 대한 걱정을 덜어줍니다. 1xBet은 또한 빠른 출금 서비스를 제공하여 사용자가 언제든지 자신의 수익을 인출할 수 있도록 돕습니다.
1xBet의 고객 지원 서비스: 사용자 지원
1xBet은 사용자가 문제를 해결할 수 있도록 강력한 고객 지원 서비스를 제공합니다. 사용자는 이메일, 전화 또는 라이브 채팅을 통해 고객 지원팀에 연락할 수 있습니다. 1xbet South Korea의 고객 지원팀은 항상 사용자를 도울 준비가 되어 있습니다. 고객 지원 서비스를 통해 사용자는 빠르고 효과적인 문제 해결 방법을 얻을 수 있습니다.
1xbet Korea 고객 지원팀은 사용자가 직면할 수 있는 다양한 문제를 해결하는 데 도움을 줄 수 있으며, 빠르고 효율적인 지원을 제공합니다. 이는 사용자가 항상 안심하고 베팅을 즐길 수 있도록 도와줍니다. 고객 지원팀은 다양한 언어를 지원하여, 사용자가 자신에게 편리한 언어로 도움을 받을 수 있습니다.
고객 지원 서비스는 사용자가 로그인 문제, 결제 문제, 기타 기술적 문제 등을 해결할 수 있도록 도와줍니다. 1xBet의 고객 지원팀은 사용자가 베팅 경험을 안전하고 원활하게 유지할 수 있도록 빠르고 효과적인 해결책을 제공합니다. 1xBet의 고객 지원팀은 플랫폼의 다양한 서비스를 사용하는 방법에 대한 조언을 제공할 수 있는 지식과 능력을 가지고 있습니다. 사용자는 언제든지 고객 지원팀에 연락하여 필요한 도움을 받을 수 있으며, 이를 통해 문제가 신속하고 효과적으로 해결됩니다.
1xBet 결제 옵션의 혜택
1xBet의 결제 과정은 간편하고 신속하게 설계되어 있어 사용자가 편리하고 안전하게 거래할 수 있습니다. 사용자는 편리한 결제 방법을 선택할 수 있으며, 개인 정보가 철저히 보호된다는 점에서 안심할 수 있습니다.
1xBet은 다양한 결제 옵션을 제공하여 사용자가 자신에게 가장 편리한 방법을 선택할 수 있도록 돕습니다. 이는 사용자가 금융 거래를 더 쉽게 관리할 수 있도록 하며, 베팅에 더 집중할 수 있도록 합니다. 또한, 1xBet은 빠른 출금 서비스를 제공하여 사용자가 자신의 수익을 빠르게 인출할 수 있도록 합니다.
1xBet은 또한 다양한 통화를 지원하여 사용자가 원하는 통화로 거래할 수 있도록 도와줍니다. 이는 국제적인 사용자에게 큰 혜택을 제공하며, 환전의 번거로움 없이 거래할 수 있도록 합니다. 이러한 다양한 결제 옵션과 지원은 1xBet을 더욱 매력적인 플랫폼으로 만듭니다.
결론: 1xBet을 사용하는 이유
1xBet은 매우 인기 있고 신뢰할 수 있는 온라인 베팅 플랫폼으로, 대한민국에서도 큰 인기를 끌고 있습니다. 다양한 기능과 서비스를 제공하여 많은 사용자에게 사랑받고 있습니다. 1xbet registration, 1xbet download, 1xbet login 및 1xbet app을 통해 사용자는 쉽게 이 플랫폼에 가입하고 다양한 스포츠와 이벤트에 베팅할 수 있습니다. 1xBet의 고객 지원 서비스와 보안 시스템은 사용자에게 안전하고 신뢰할 수 있는 베팅 경험을 보장합니다.
1xBet을 사용하면 사용자는 새로운 베팅 경험을 즐길 수 있으며, 이는 그들에게 새로운 즐거움과 흥분을 더해줍니다. 이 플랫폼은 다양한 보너스와 프로모션을 제공하여 베팅 경험을 더욱 유익하게 만듭니다. 1xbet South Korea 플랫폼을 통해 사용자는 쉽게 다양한 스포츠와 이벤트에 베팅하고 보상을 받을 수 있습니다. 1xBet의 기능과 서비스는 사용자가 포괄적인 베팅 경험을 즐길 수 있도록 하여 안전하고 신뢰할 수 있는 플랫폼임을 보장합니다.
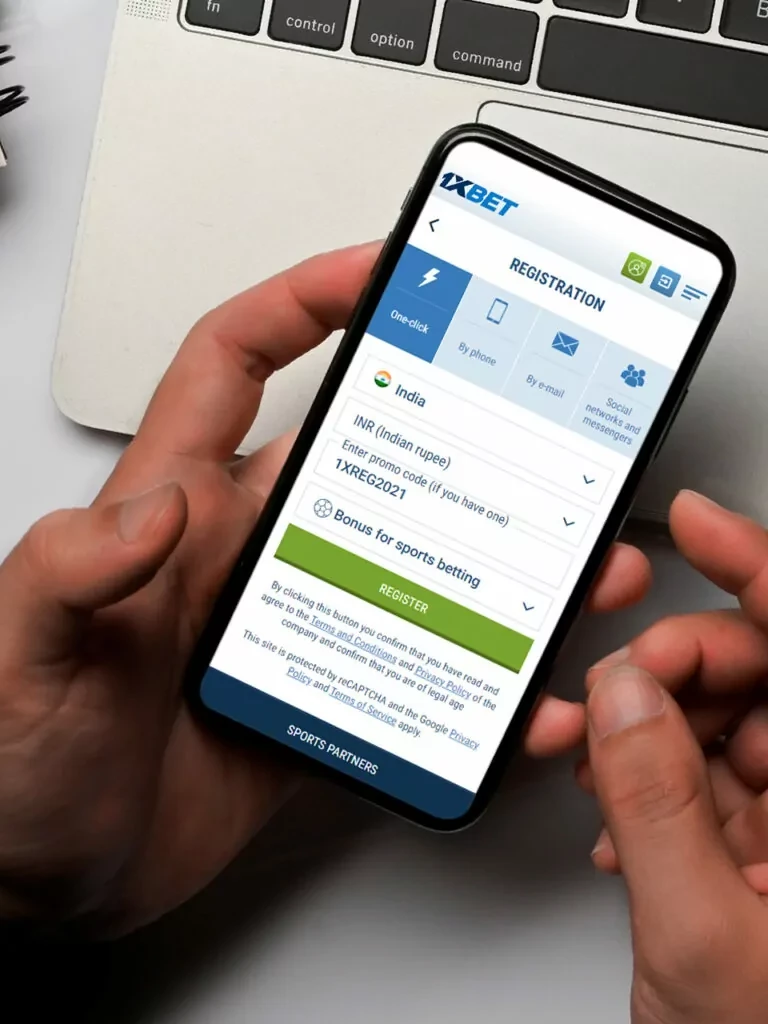
1xBet 사용의 이점
1xBet을 사용하면 사용자는 새로운 베팅 경험을 즐길 수 있으며, 이는 그들에게 새로운 즐거움과 흥분을 더해줍니다. 이 플랫폼은 다양한 보너스와 프로모션을 제공하여 베팅 경험을 더욱 유익하게 만듭니다. 1xbet Korea 플랫폼을 통해 사용자는 쉽게 다양한 스포츠와 이벤트에 베팅하고 보상을 받을 수 있습니다. 1xBet의 기능과 서비스는 사용자가 포괄적인 베팅 경험을 즐길 수 있도록 하여 안전하고 신뢰할 수 있는 플랫폼임을 보장합니다.
1xBet의 주요 기능과 혜택에는 다음과 같은 것들이 포함됩니다.
- 다양한 스포츠와 카지노 게임에 베팅할 수 있는 기회 제공: 1xBet은 사용자에게 축구, 농구, 테니스, 크리켓 등 다양한 스포츠 이벤트에 베팅할 수 있는 기회를 제공합니다. 또한, 사용자는 룰렛, 블랙잭, 포커 등 다양한 카지노 게임도 즐길 수 있습니다.
- 모바일 앱을 통해 언제 어디서나 베팅 가능: 1xbet app을 통해 사용자는 언제 어디서나 모바일 기기를 사용하여 쉽게 베팅할 수 있습니다. 이는 사용자가 이동 중에도 베팅을 할 수 있게 해주며, 더 많은 베팅 기회를 제공합니다.
- 사용자에게 보너스와 프로모션 제공: 1xBet은 신규 사용자와 기존 사용자 모두를 위한 다양한 보너스와 프로모션을 제공합니다. 이는 사용자가 더 많은 베팅 기회를 가지고, 더 많은 수익을 올릴 수 있도록 돕습니다.
- 간편하고 안전한 결제 옵션: 1xBet은 다양한 결제 옵션을 제공하여 사용자가 편리하게 입출금을 할 수 있도록 돕습니다. 또한, 모든 거래는 고도로 암호화되어 안전하게 보호됩니다.
- 현지 통화와 한국어 지원: 1xbet Korea는 현지 통화를 지원하여 사용자들이 환전의 번거로움 없이 거래할 수 있도록 합니다. 또한, 한국어 지원을 통해 사용자가 더 쉽게 플랫폼을 사용할 수 있습니다.
- 다양한 문제를 해결해주는 강력한 고객 지원 서비스: 1xBet의 고객 지원팀은 사용자가 직면할 수 있는 다양한 문제를 해결하는 데 도움을 줄 수 있으며, 빠르고 효율적인 지원을 제공합니다.
이 모든 기능과 서비스는 1xBet을 대한민국에서 최고의 온라인 베팅 플랫폼 중 하나로 만듭니다. 이 플랫폼을 통해 사용자는 안전하고 흥미롭고 유익한 베팅 경험을 즐길 수 있습니다. 1xbet registration, 1xbet download, 1xbet login 및 1xbet app을 통해 이 플랫폼에 가입하여 다양한 스포츠와 이벤트에 베팅할 수 있습니다.
1다른 언어로 xBet:
- 1xBet in Ethiopia: 1xBet Ethiopia
- 1xBet in Côte d’Ivoire: 1xBet Côte d’Ivoire
- 1xBet in Rwanda: 1xBet Rwanda
- 1xBet in Sierra Leone: 1xBet Sierra Leone
- 1xBet in Tanzania: 1xBet Tanzania
- 1xBet in Saudi Arabia: 1xBet Saudi Arabia
- 1xBet in Liberia: 1xBet Liberia
- 1xBet in Senegal: 1xBet Senegal
- 1xBet in Morocco: 1xBet Morocco
- 1xBet in Uganda: 1xBet Uganda
최종 결론
1xBet은 포괄적이고 안전한 온라인 베팅 플랫폼으로, 대한민국에서 매우 인기가 있습니다. 다양한 기능과 서비스가 사용자에게 안전하고 흥미롭고 유익한 베팅 경험을 제공합니다. 베팅을 즐기는 사람이라면 1xbet registration, 1xbet download, 1xbet login 및 1xbet app을 통해 이 플랫폼에 가입하고 다양한 스포츠와 이벤트에 베팅해 보세요.
1xBet을 통해 사용자는 새로운 베팅 경험을 즐길 수 있으며, 이는 그들에게 새로운 즐거움과 흥분을 더해줍니다. 이 플랫폼은 다양한 보너스와 프로모션을 제공하여 베팅 경험을 더욱 유익하게 만듭니다. 1xbet Korea 플랫폼을 통해 사용자는 쉽게 다양한 스포츠와 이벤트에 베팅하고 보상을 받을 수 있습니다. 1xBet의 기능과 서비스는 사용자가 포괄적인 베팅 경험을 즐길 수 있도록 하여 안전하고 신뢰할 수 있는 플랫폼임을 보장합니다.